¶ Warunki dostępu
Wymagania:
- konto na platformie e-science.pl
- aktywna usługa "Przetwórz na Superkomputerze"
¶ Terminal
¶ Sprawdź czy posiadasz dostęp do GPU
Zaloguj się na serwer dostępowy:
ssh uzytkownik@ui.wcss.pl
Sprawdź bilans usług:
service-balance --check-gpu
Przykładowy wynik komendy z dostępem do GPU:
GPU AVAILABLE FOR: hpc-xxxxx-123456789
Jeśli nie spełniasz powyższych wymagań kliknij tutaj
¶ Zadanie interaktywne
Uruchom zadanie interaktywne z akceleratorem GPU:
sub-interactive-lem-gpu
Wylistuj dostępne karty graficzne:
nvidia-smi
Wynik komendy:
Wed Apr 2 12:41:26 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.124.06 Driver Version: 570.124.06 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 Off | 00000000:66:00.0 Off | 0 |
| N/A 33C P0 69W / 700W | 1MiB / 95830MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
¶ PyTorch w kontenerze
¶ W zadaniu interaktywnym
- Zaloguj się na ui.wcss.pl:
ssh uzytkownik@ui.wcss.pl
- Uruchom zadanie interaktywne:
srun -N 1 -c 4 --mem=10gb -t60 -p lem-gpu --gres=gpu:hopper:1 --pty /bin/bash
- Uruchom kontener z poleceniem
nvidia-smi:
apptainer exec --nv /lustre/software-data/container-images/pytorch_latest.sif obliczenia_skrypt.py
¶ W zadaniu wsadowym
- Zaloguj się na ui.wcss.pl:
ssh uzytkownik@ui.wcss.pl
- Wyślij zadanie do kolejki ( przeczytaj o [systemie kolejkowym SLURM] (https://man.e-science.pl/pl/kdm/slurm)) przygotowując odpowiedni skrypt.
Przykładowy skrypt Stwórz plik zadanie-testowe.sh:
#!/bin/bash
#SBATCH -N 1
#SBATCH -c 4
#SBATCH --mem=10gb
#SBATCH --time=0-01:00:00
#SBATCH --job-name=example
#SBATCH -p lem-gpu
#SBATCH --gres=gpu:hopper:1
apptainer exec --nv /lustre/software-data/container-images/pytorch_latest.sif obliczenia_skrypt.py
- Uruchom zadanie wsadowe komendą
sbatchi odczytaj plik wyjściowy:
sbatch zadanie-testowe.sh
¶ Dowolne oprogramowanie naukowe
¶ Subskrypty
Specjalnie przygotowane skrypty do uruchamiania poszczególnych wersji danego programu na zasobach GPU.
Lista subskryptów
Wpisz nazwę subskryptu i kliknij przycisk Enter - uzyskasz informację o parametrach.
Przykład skryptu dla programu MATLAB wersji r2022b, sub-matlab-R2022b:
login@ui: ~ $ sub-matlab-R2022b
Usage: /usr/local/bin/bem2/sub-matlab-R2022b [PARAMETERS] INPUT_FILE MOLECULE_FILE
Parameters:
-p | --partition PARTITION Set partition (queue). Default = normal
-n | --nodes NODES Set number of nodes. Default = 1
-c | --cores CORES Up to 48. Default = 1
-m | --memory MEMORY In GB, up to 390 (must be integer value). Default = 1
-t | --time TIME_LIMIT In hours. Default = 1
Uruchom skrypt, wybierając partycję lem-gpu - przykładowy skrypt :
sub-matlab-R2022b -p lem-gpu -n 1 -c 1 -m 3 -t 50
¶ Moduły
Załadowanie przykładowego modułu:
module load molpro/2024.1.1
¶ JupyterLab z PyTorch
- Zaloguj się na https://ood.e-science.pl
- Wybierz aplikację
Jupyterlab z PyTorch:
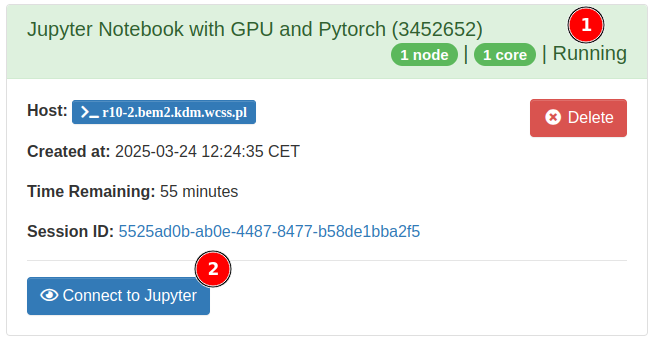
- Kliknij
Launch - Poczekaj aż status zadania zmieni się na
Running(1) i kliknijConnect to Jupyter(2)
W przeglądarce otworzy się nowe okno z interfejsem JupyterLab.
¶ Mam problem z...
- Brak konta e-science Jeśli nie masz konta e-science zarejestruj się.
- Brak usługi Przetwórz na Superkomputerze Złóż wniosek o nową usługę lub modyfikację istniejącej.
- Brak dostępu do GPU w ramach aktywnej usługi Złóż wniosek o zwiększenie zasobów w wybranej usłudze
- Skończyły się godziny GPU w usłudze Złoż wniosek o zwiększenie zasobów
¶ Zobacz również
- Kto może zostać użytkownikiem Superkomputera?
- Jak uzyskać dostep do Superkomputera?
- Wnioski o usługę Instrukcje jak wypełnić formularze online
- users.e-science.pl Zarządzanie zespołem, użytkownikami i prawami dostępu
- OpenOnDemand Dostęp graficzny do aplikacji na Superkomputerze
- Rejestr zużycia zasobów Jak sprawdzić dostępne zasoby w usłudze
- HPC info Szczegółowe informacje o użyciu zasobów w zadanich i usługach
- set-default-service Zmiana domyślnej usługi przy zlecaniu zadań
- Subskrypty specjalne przygotowane skrypty do uruchamiania poszczególnych wersji danego programu
- Partycje lista partycji GPU i sprawdzanie dostępności węzłów
- Moduły Jak korzystać z polecenia module
Pełna wersja dokumentacji użytkownika znajduje się tutaj.
Jeśli nie znajdziesz rozwiązania w powyżej dokumentacji, prosimy o kontakt z kdm@wcss.pl.