¶ S3 (Simple Storage Service)
S3 to usługa przestrzeni składowania danych, zapewniająca interfejs API - kompatybilny z Amazon Web Services (AWS). MinIO to oparta na chmurze usługa przechowywania obiektów, pozwalająca użytkownikom na przechowywanie i pobieranie danych, obsługująca wszystkie podstawowe funkcje S3.
System przechowywania danych w modelu obiektowym (S3) przeznaczony jest przede wszystkim do integracji z aplikacjami, backupów i zarządzania dużymi zbiorami danych. Nie działa jak typowy webdysk – dostęp do danych odbywa się w ramach przydzielonych polityk, a operacje wykonuje się za pomocą klienta S3 lub API S3. Wszystkie działania są kontrolowane i ograniczone zgodnie z nadanymi uprawnieniami.
¶ Najważniejsze pojęcia w S3:
S3 (Simple Storage Service)- usługa pamięci masowej, umożliwia przechowywanie i łatwy dostęp do danych.
Bucket – to kontener, w którym przechowuje się obiekty. Przestrzeń wykorzystywana przez bucket oraz dostęp do niego są zarządzalne.
Obiekty – pliki przechowywane w bucketach.
Klucz – unikalny identyfikator obiektu. Każdy obiekt w S3 można wyróżnić po kombinacji nazwy bucketu, klucza i - opcjonalnie - identyfikatorze wersji danego obiektu.
Chęć korzystania z przestrzeni składowania danych, w ramach usług świadczonych przez WCSS, należy deklarować przez stronę https://e-science.pl (usługa „Przechowaj dane w chmurze”).
Instrukcja zakładania konta E-SCIENCE.PL ››
Instrukcja składania wniosków o usługę ››
Dostęp do uslugi jest możliwy przez interfejs webowy oraz popularne programy klienckie obsługujące protokół S3, a także dostępne bilioteki programistyczne oraz narzędzia i frameworki kompatybilne z MinIO oraz wykorzystujące backend S3.
¶ Interfejs webowy
¶ Logowanie
Aby zalogować się do interfejsu webowego MinIO należy wejść na stronę zgodnie z poniższą tabelą (należy wybrać endpoint w zależności od przypisania usługi - wg informacji podanej w e-mailu potwierdzającym przyznanie usługi oraz w na stronie https://e-science.pl/projekty-uzytkownika/), a następnie użyć poświadczeń do konta e-science.pl.
| Endpoint S3 | Interfejs webowy | Dostępność | Uwagi |
|---|---|---|---|
| https://s3min.e-science.pl | https://console.s3min.e-science.pl | VPN KDM, sieć WASK | Usługi założone przed 02.2025 r. |
| https://s3min2.e-science.pl | https://console.s3min2.e-science.pl | Internet | Usługi założone po 02.2025 r. |

¶ Przeglądanie obiektów
Zakładka Object Browser zawiera listę bucketów (nazwę - Name, liczbę obiektów - Objects, rozmiar - Size oraz rodzaj dostępu - Access), które należą do danego użytkownika. W przypadku, gdy bucketów jest dużo, można użyć wyszukiwarki, celem szybszego znalezienia poszukiwanego zasobu.
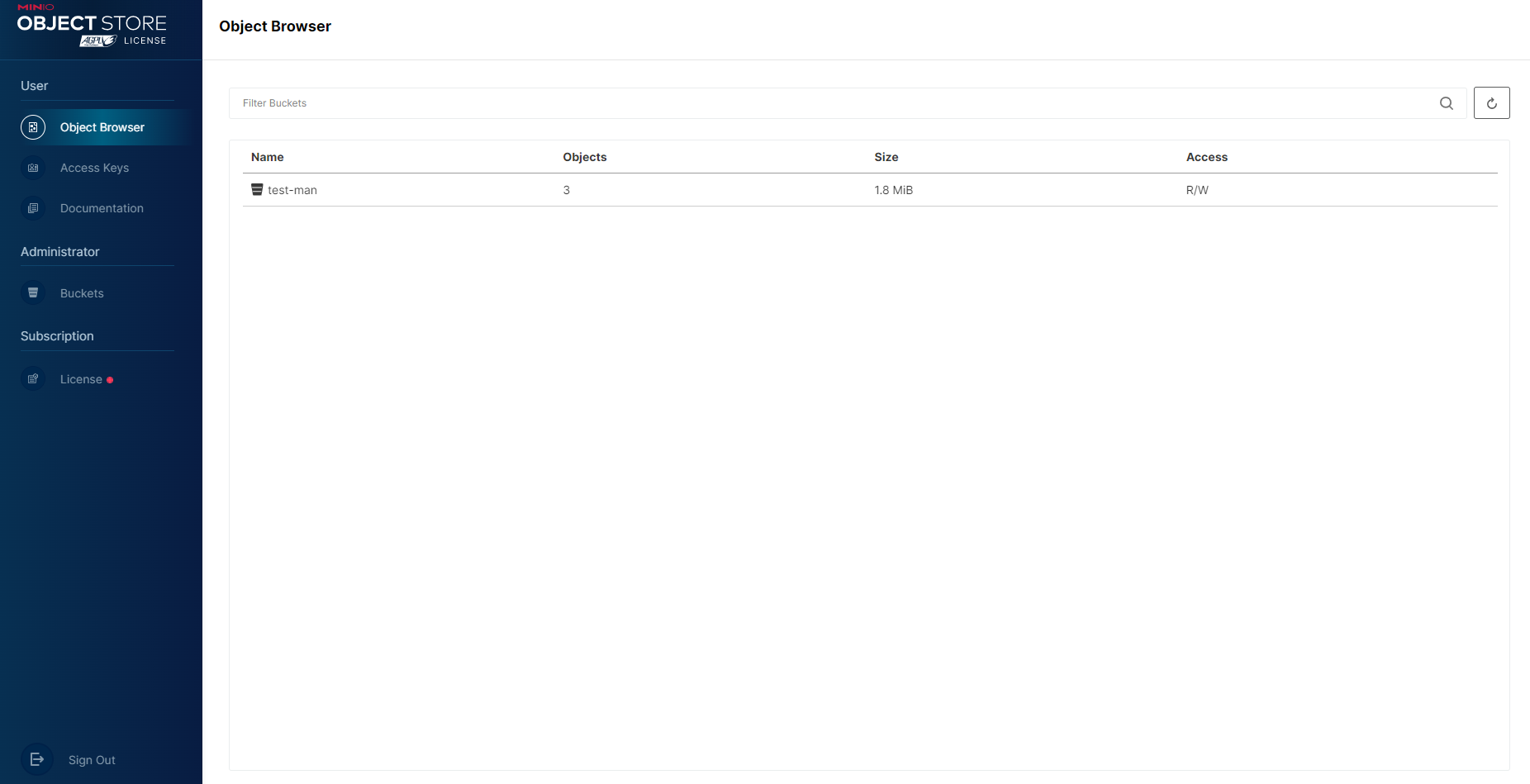
Po wybraniu konkretnego bucketu pojawiają się informacje na jego temat (data utworzenia - Created on, rodzaj dostęp - Access, rozmiar oraz liczba obiektów), a także lista obiektów dodanych do bucketu zawierająca: nazwę obiektu, datę ostatniej modyfikacji oraz rozmiar obiektu.
Po prawej stronie znajdują się przyciski:
- Rewind - przewijanie do i wybór konkretnej daty;
- Refresh - odświeżenie listy obiektów;
- Upload - dodawanie nowych obiektów/folderów.
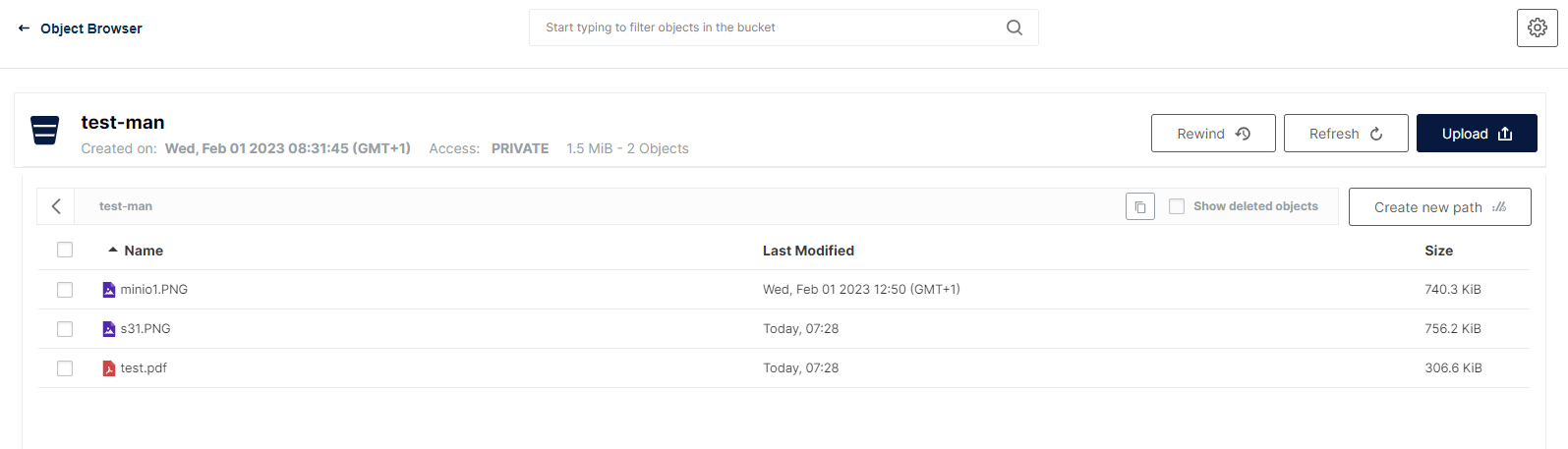
Po kliknięciu ikonki obiektu pojawiają się opcje:
- Download - pobranie;
- Share - udostępnianie;
- Preview - podgląd;
- Delete - usunięcie obiektu.

Po wyborze obiektu istnieje możliwość również na podejrzenie szczegółowych informacji na jego temat, w tym - metadanych. Oprócz opcji opisanych wyżej można również otagować obiekt.
¶ Klucze dostępowe
Klucze dostępu to tożsamości potomne uwierzytelnionego użytkownika, w związku z czym mają one takie same lub mniejsze uprawnienia od właściciela.
Użytkownik może wygenerować dowolną liczbę kluczy dostępu, przy czym akcja ta może się odbyć bez udziału administratorów usługi.
Domyślnie podczas tworzenia klucza ma on takie same uprawnienia, co użytkownik - najczęściej read/write. Zmienianie polityki kluczy dostępowych wyjaśnione jest w sekcji Zarządzanie dostępem.
¶ Tworzenie nowych kluczy dostępowych
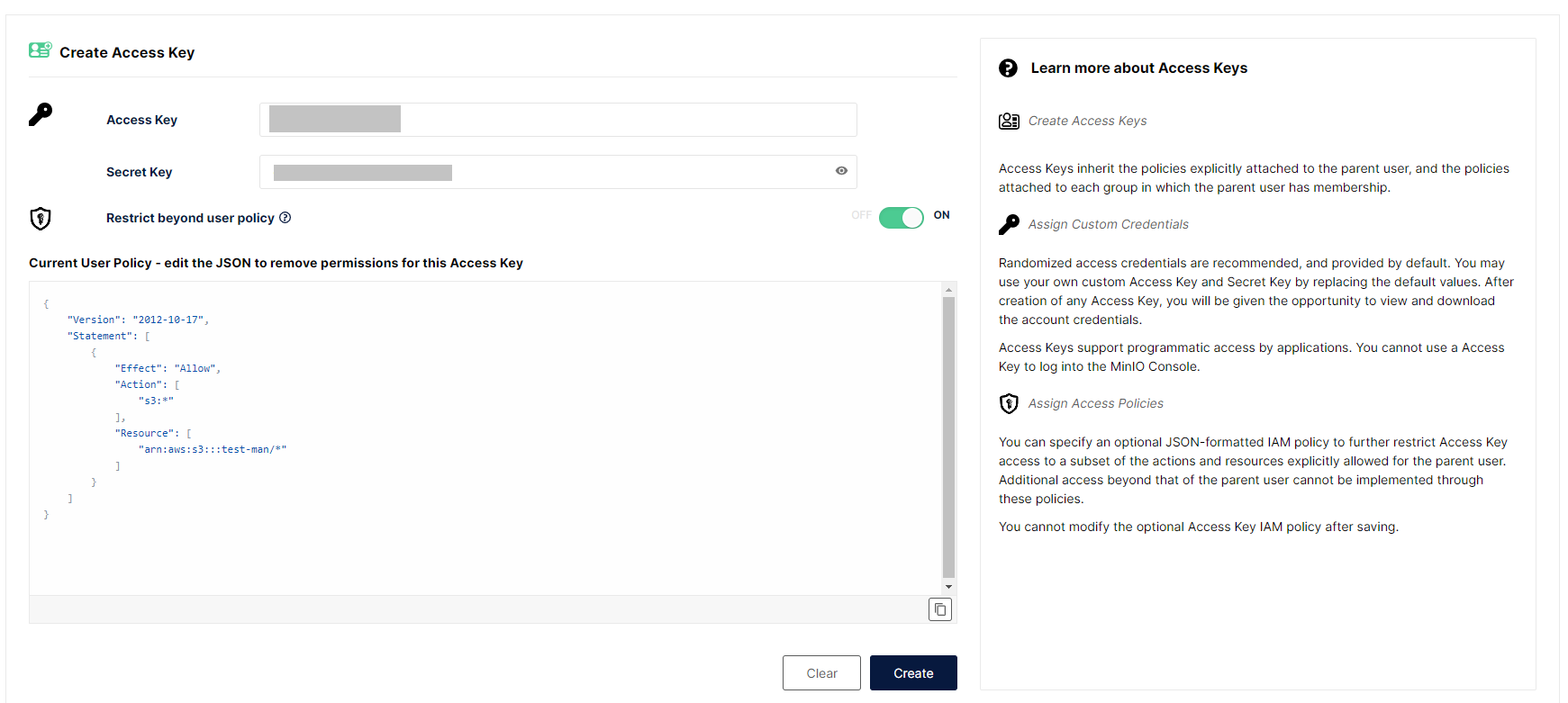
W celu utworzenia nowego klucza dostępowego, należy:
- Kliknąć zakładkę Access Keys;
- Następnie nacisnąć przycisk Create access key +;

- Opcjonalnie dodać własną policy poprzez ustawienie opcji Restrict beyond user policy na ON oraz wpisanie treści w polu tekstowym pliku JSON;
- Nacisnąć Create.
5. Skopiować i zapisać Access Key oraz Secret Key lub ściągnąć plik (przycisk Download for import)
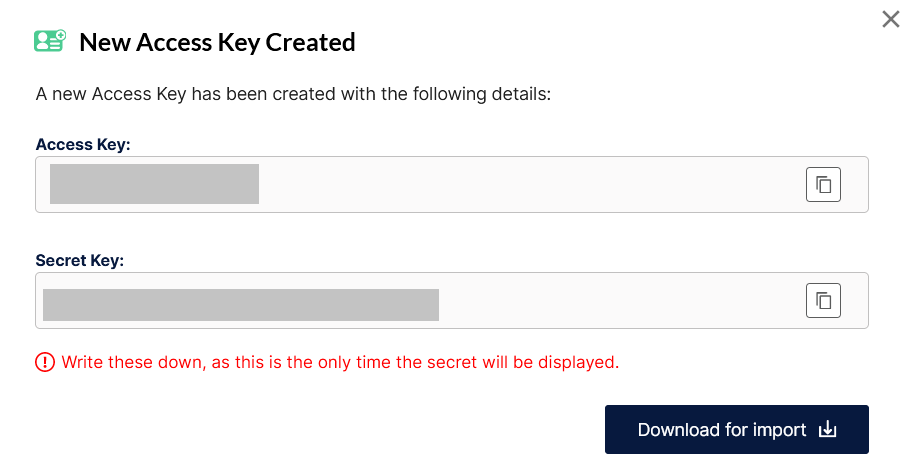
Prywatny klucz (Secret Key) widoczny jest dla użytkownika tylko w procesie tworzenia nowego klucza dostępowego, dlatego tak ważne jest, aby go zapisać (utrwalić).
¶ Widok główny
Na ekranie głównym kluczy dostępowych (Access Keys) znajduje się lista wygenerowanych kluczy przez użytkownika. W przypadku, gdy kluczy jest dużo, można użyć wyszukiwarki, celem szybszego znalezienia poszukiwanego.
W prawym, górnym rogu można dodać nowy klucz dostępu Create access key + (opisane w rozdziale Tworzenie nowych kluczy dostępu).
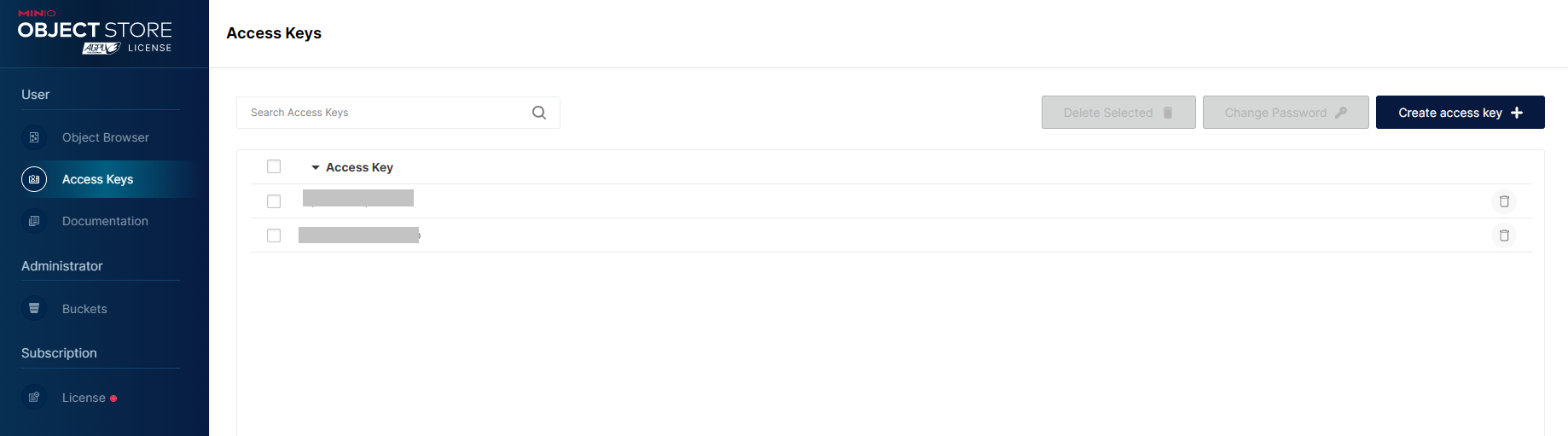
W celu usunięcia klucza/y dostępu należy:
- przy kluczu do usunięcia nacisnąć ikonkę śmietnika;
- zaznaczyć klucze do usunięcia i nacisnąć Delete Selected.

Zmiana policy klucza po jego utworzeniu nie jest możliwa ze względów bezpieczeństwa. W przypadku potrzeby modyfikacji uprawnień należy usunąć istniejący klucz i utworzyć nowy z właściwą policy.
¶ Bucket
Zakładkę Buckets można znaleźć, po lewej stronie, w sekcji Administrator. Na ekranie głównym pojawią się informacje ogólne na temat dostępnych dla danego użytkownika bucketów, a wraz z tym możliwość skonfigurowania np. szyfrowania (Encryption), włączenia wersjonowania (Versioning) i polityki dostępu (Access Policy).
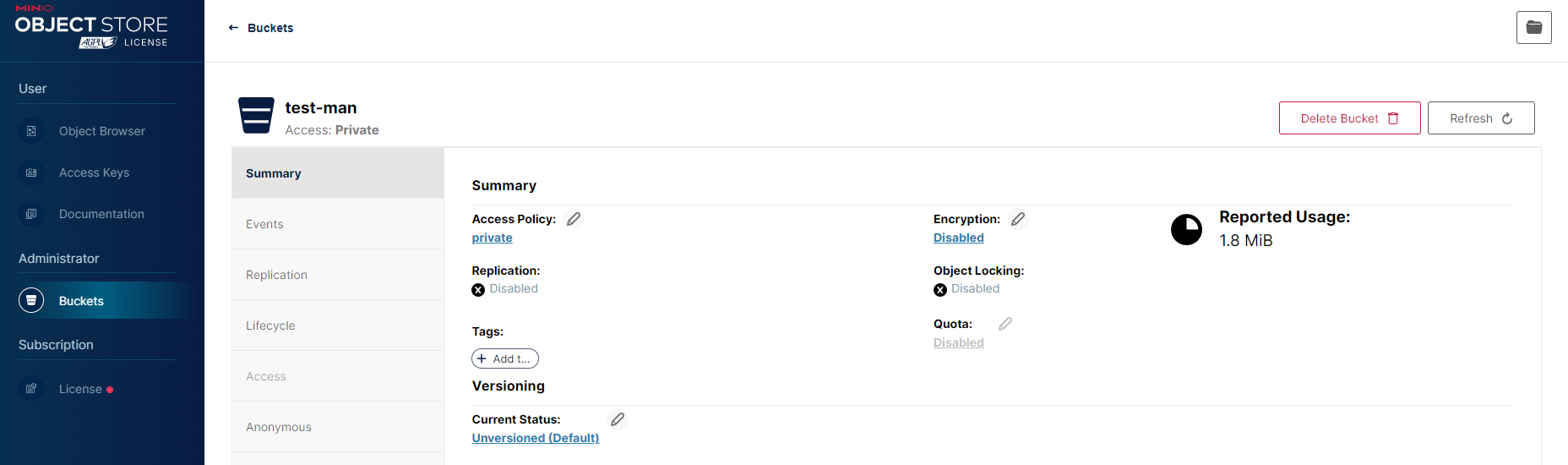
Każdy dostępny dla konkretnego użytkownika bucket składa się z następujących sekcji:
- Summary - podsumowanie;
- Events - zdarzenia;
- Replication - replikacja;
- Lifecycle - cykl życia;
- Anonymous - anonimowy dostęp.
¶ Summary
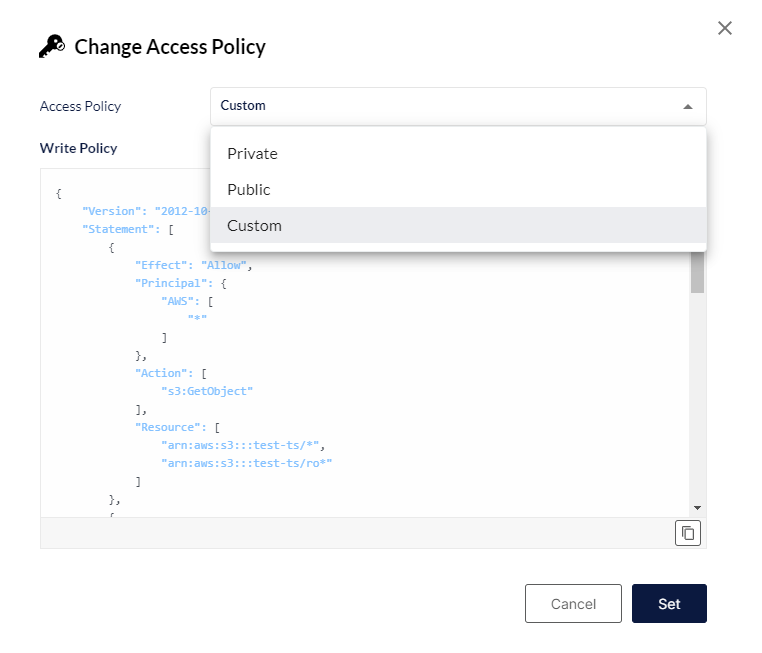
¶ Polityka dostępu
Do wyboru są 3 opcje:
- Private (prywatna) - dane dostępne tylko dla ich twórcy;
- Public (publiczna) - każda osoba będzie miała dostęp do danych;
- Custom - tworzona za pomocą pliku JSON.
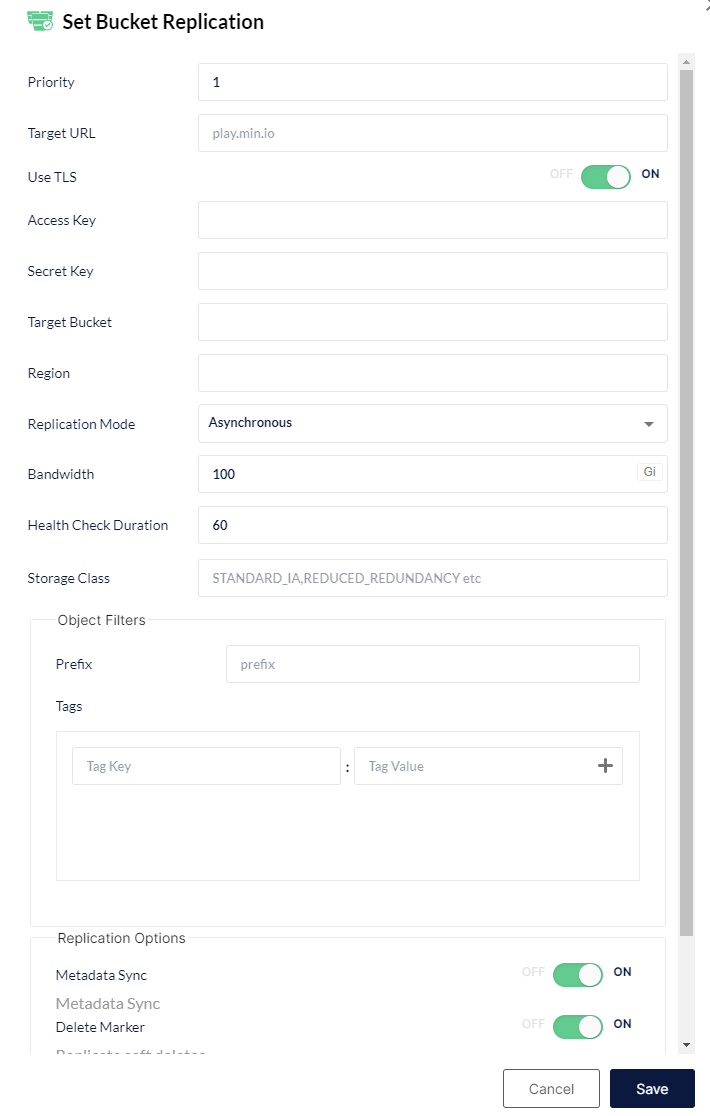
¶ Replication
Replikacja to funkcja S3, która pozwala automatycznie skopiować zawartość jednego bucketu do innego, co można wykorzystać np. do tworzenia kopii zapasowych, odzyskiwania danych, czy dystrybucji i przetwarzania danych.
Replikacja bucketów synchronizuje dane na ich poziomie (ścieżki i pliki).
¶ Dodawanie reguły replikacji
W celu skonfigurowania dwukierunkowej replikacji zasobników przy użyciu MinIO należy utworzyć nową regulę replikacji, nacisnąć przycisk Add Replication Rule +. Następnie wypełnić pola i zapisać, używając przycisku: Save.
¶ Lifecycle
Cykl życia pozwala na zdefiniowanie reguł dotyczących przenoszenia, archiwizacji lub usuwania obiektów na podstawie ich wieku, typu, rozmiaru lub innych atrybutów.
Poniżej pokazano przykład usuwania obiektów w ścieżce o zadanych parametrach - starszych niż 5 dni.
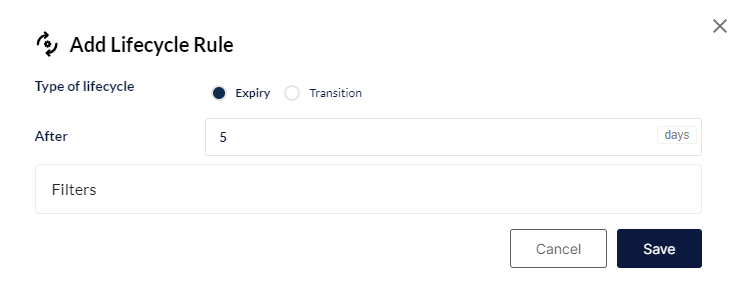
¶ Anonymous
Funkcja anonimowego dostępu pozwala na udostępnienie zawartości bucketu poprzez link, należy kliknąć Add Access Rule +.
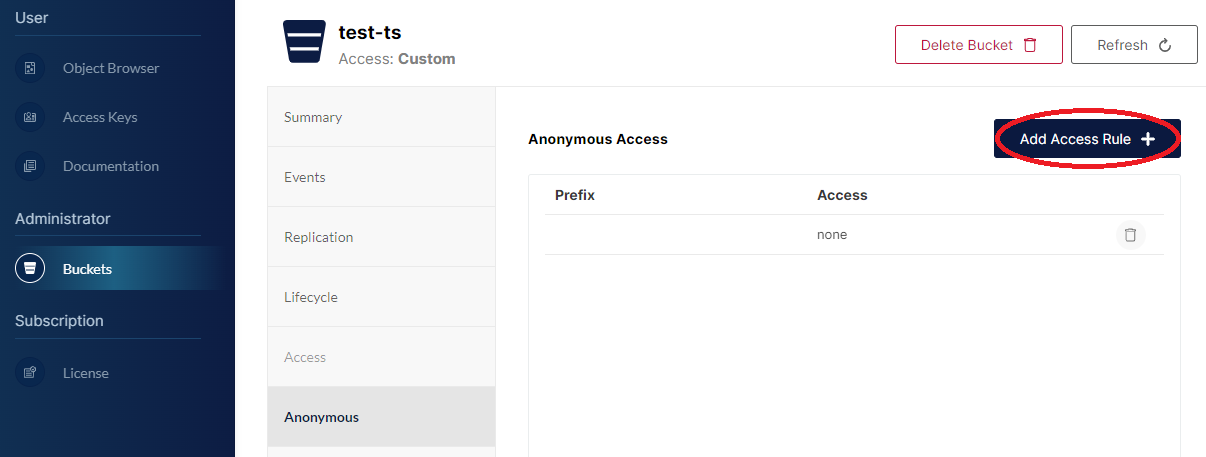
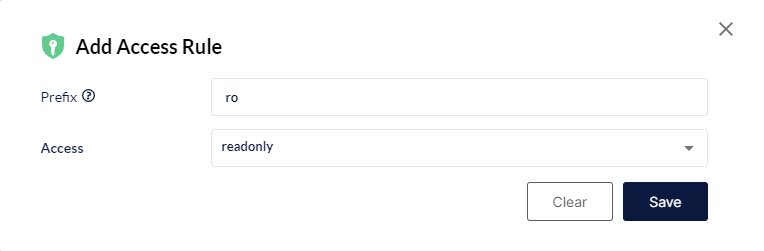
Następnie ograniczyć poziom dostępu do: read-only, read-write oraz write-only.
¶ Zarządzanie dostępem
Usługa MinIO, do definiowania autoryzowanych akcji i zasobów (do których ma dostęp uwierzytelniony użytkownik), wykorzystuje Policy-Based Access Control (PBAC). Jest to schemat analogiczny, co dokumenty zasad AWS IAM.
Przykładowy szablon do tworzenia zasad niestandardowych, dla struktury polityki użytkownika:
{
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [ "s3:<nazwa_akcji>", ... ],
"Resource" : "arn:aws:s3:::*",
"Condition" : { ... }
},
{
"Effect" : "Deny",
"Action" : [ "s3:<nazwa_akcji>", ... ],
"Resource" : "arn:aws:s3:::*",
"Condition" : { ... }
}
]
}
Możliwe do wykonania akcje zostały omówione w rozdziale Built-In Policies.
W celu zastosowania polityki uprawnień do wybranego bucketu należy, w źródle (Resource), przed gwiazdką, umieścić nazwę bucketu i slash (/).
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [ "s3:*"],
"Resource" : "arn:aws:s3:::<nazwa_bucketu>/*",
"Condition" : { ... }
}
]
}
Chcąc udostępnienić konkretny plik/katalog z bucketu, należy przy źródle - Resource, przed gwiazdką, wpisać nazwę bucketu (test-man) i /, następnie ścieżkę do obiektu lub ścieżki (test-folder) i /.
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [ "s3:<NazwaBucketu>", ... ],
"Resource" : "arn:aws:s3:::test-man/test-folder/*",
"Condition" : { ... }
}
]
}
¶ Built-In Policies
MinIO udostępnia następujące polityki do przypisania do użytkowników:
- read-only;
- read-write;
- write-only.
¶ Read-only
Opcja przyznaje uprawnienia tylko do odczytu dla dowolnego obiektu. Akcja (Action) GET musi odnosić się do określonego obiektu.
s3:GetBucketLocation
s3:GetObject
Przykład:
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource" : "arn:aws:s3:::<nazwa_bucketu>/*",
"Condition" : { ... }
}
]
}
¶ Read-write
Przyznaje uprawnienia do odczytu i zapisu dla wszystkich obiektów na serwerze MinIO.
s3:*
Przykład:
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"s3:*"
],
"Resource" : "arn:aws:s3:::<nazwa_bucketu>/*",
"Condition" : { ... }
}
]
}
¶ Write-only
Przyznaje uprawnienia tylko do zapisu do dowolnej przestrzeni nazw. Akcja PUT musi odnościć się do konkretnej lokalizacji obiektu, natomiast nie ma wymogu jej wpisywania.
s3:PutObject
Przykład:
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"s3:PutObject"
],
"Resource" : "arn:aws:s3:::<nazwa_bucketu>/*",
"Condition" : { ... }
}
]
}
¶ Konfiguracja klienta rclone
Konfiguracja klienta rclone jest opisana w osobnym artykule.
¶ Konfiguracja klienta WinSCP
WinSCP to graficzny klient dla systemu Windows obsługujący protokół S3, oferuje funkcje menadżera plików i synchronizacji.
¶ Windows
- Należy pobrać oprogramowanie ze strony producenta: https://winscp.net/eng/download.php i zainstalować na komputerze
- Następnie uruchomić program i w oknie nowej sesji skonfigurować połączenie wybierając protokół Amazon S3
- Wpisać nazwę hosta (zgodnie z przypisaniem) oraz numer portu 443
| Endpoint S3 | Uwagi |
|---|---|
| s3min.e-science.pl | Usługi założone przed 02.2025 r. |
| s3min2.e-science.pl | Usługi założone po 02.2025 r. |
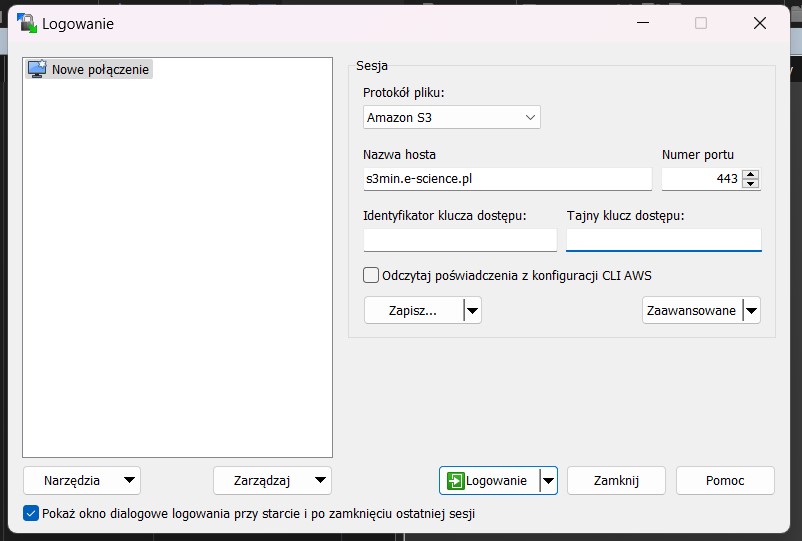
- Podać Identyfikator klucza dostępu oraz Tajny klucz dostępu (utworzone podczas generowania kluczy Access Keys)
- Klikając przycisk Zaawansowane, następnie Środowisko S3 - Opcje protokołu - Styl adresu URL - zmienić na Ścieżka i zapisać przyciskiem OK
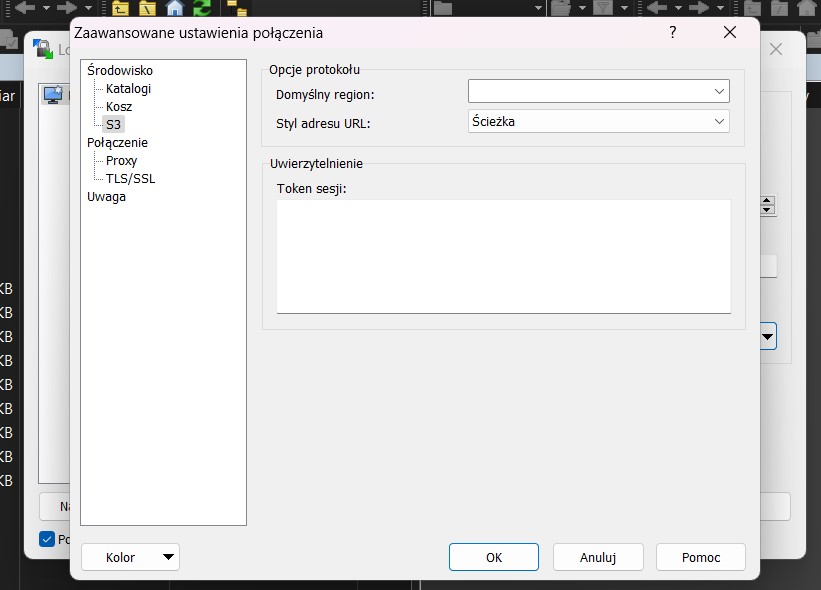
- Na końcu należy zapisać połaczenie pod wybraną nazwą klikając przycisk Zapisz.
- Następnie należy połączyć się z usługą s3 za pomocą przycisku "Logowanie" na dole okna połaczenia.
¶ Konfiguracja klienta CyberDuck
CyberDuck to darmowy program do zarządzania plikami na serwerach S3. Oferuje prosty, intuicyjny interfejs graficzny. Program wspiera następujące systemy operacyjne: Windows, Linux oraz MacOS.
¶ Windows/Mac
- Pobrać i zainstalować aplikację CyberDuck (https://cyberduck.io/download/)
- Uruchomić CyberDuck
- Wybrać Edycja - Preferencje - Profile
- Odszukać profil S3 (Deprecated path style requests) oraz zaznaczyć przy nim checkbox, następnie zamknąć okno preferencji
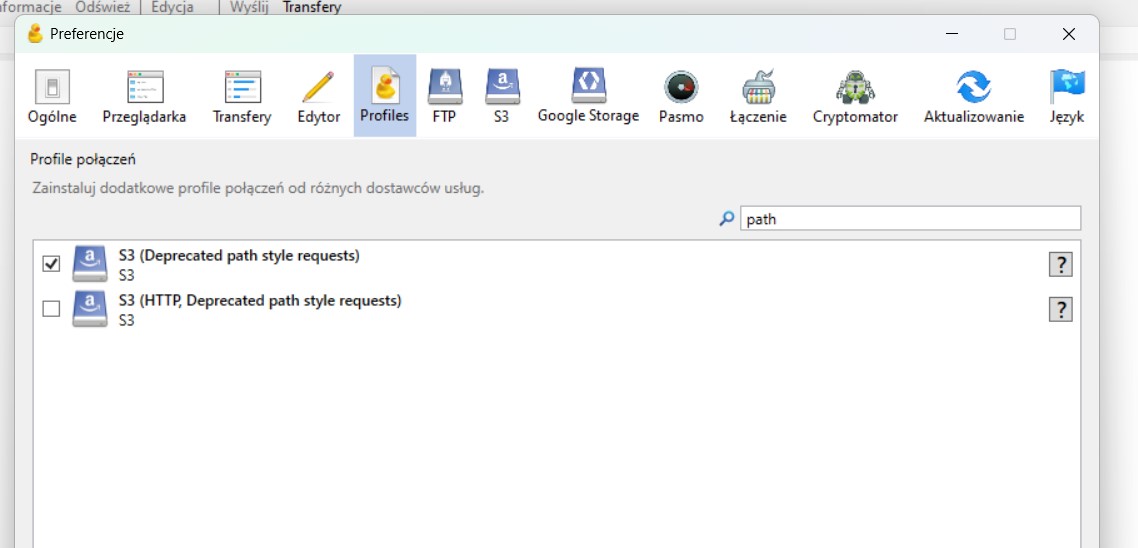
- W oknie głównym kliknąć Otwórz połączenie
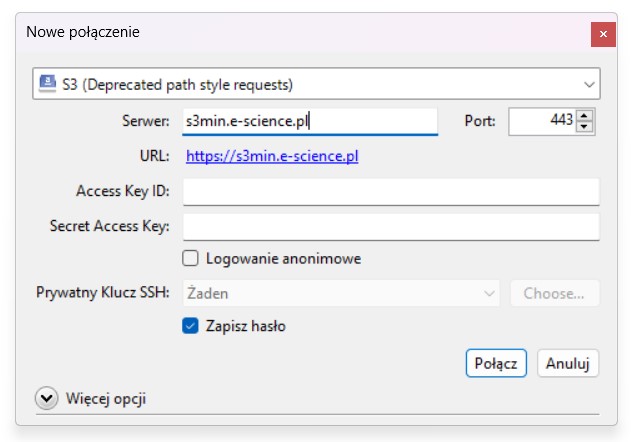
- Domyślnie ustawione jest nowe połączenie FTP, należy zmienić na S3 (Deprecated path style requests)
- Wpisać adres serwera MinIO (zgodnie z przypisaniem)
| Endpoint S3 | Uwagi |
|---|---|
| s3min.e-science.pl | Usługi założone przed 02.2025 r. |
| s3min2.e-science.pl | Usługi założone po 02.2025 r. |
- Zmienić port na port API S3 (port 443)
- Wpisać Access Key ID oraz Secret Access Key (utworzone podczas generowania kluczy Access Keys)
- Wpisać nazwę bucketu w Path (opcjonalnie)
- Zatwierdzić przyciskiem Connect
¶ Linux
Instrukcja instalacji znajduje sie na stronie https://docs.duck.sh/cli/
Przykładowa instalacja z użyciem repozytorium paczek DEB na systemie Ubuntu:
- Dodanie nightly albo stabilnej wersji repozytorium duck do /etc/apt/sources.list.
deb https://s3.amazonaws.com/repo.deb.cyberduck.io nightly main
deb https://s3.amazonaws.com/repo.deb.cyberduck.io stable main
- Pobranie klucza GPG z keyserver.ubuntu.com, w celu weryfikacji integralności paczek.
echo -e "deb https://s3.amazonaws.com/repo.deb.cyberduck.io stable main" | sudo tee /etc/apt/sources.list.d/cyberduck.list > /dev/null
- Synchronizacja repozytorium
sudo apt-get update
- Instalacja
sudo apt-get install duck
¶ Lokalne montowanie bucketów w systemach Linux
Istnieje możliwość lokalnego zamontowania bucketu S3 w danym systemie (Linux) i korzystania z niego w tradycyjny sposób, tzn. jako lokalny dysk twardy, bez potrzeby korzystania z dodatkowych interfejsów czy aplikacji. Umożliwia to efektowną operacje na plikach z wykorzystaniem Linuxowych komend, takich jak mv, cp, rm czy mkdir.
UWAGA! Po lokalnym zamontowaniu bucketu S3, zmiany w plikach na zamontowanym buckecie są trwałe!
Popularne programy do lokalnego montowania bucketów S3 w systemach Linux to goofys oraz s3fs.
¶ Konfiguracja
Przed operacją montowania należy utworzyć plik pod ścieżką ~/.aws/credentials zawierający dane do uwierzytelniania (Access Key ID oraz Secret Access Key).
Zawartość pliku ~/.aws/credentials:
[default]
aws_access_key_id = <ACCESS_KEY_ID>
aws_secret_access_key = <SECRET_ACCESS_KEY>
gdzie <ACCESS_KEY_ID> oraz <SECRET_ACCESS_KEY> należy zastąpić prawdziwym zestawem kluczy dostępowych (zobacz Sekcję Klucze dostępowe).
¶ Montowanie bucketu
¶ w Nextcloud
Poniższa instrukcja opisuje, jak zamontować bucket S3 (MinIO) w Nextcloud.
¶ Generowanie kluczy dostępu:
W pierszym kroku należy wygenerować klucze dostępowe do bucketu S3. W tym celu należy otworzyć przeglądarkę internetową a następnie wejść na stronę panelu administracyjnego S3 (MinIO).
Adres ten można sprawdzić wyświetlając dane szczegółowe o wybranej usłudze "Przechowaj dane w chmurze" Adres ten powinien wyglądać na wzór tego: s3min.e-science.pl. Otwierając adres w przeglądarace konieczne będzie zalogoawnie się na swoje konto.
SZCZEGÓŁOWA INSTRUKCJA generowania kluczy dostępowych
- System wygeneruje Access Key oraz Secret Key. Należy pobrać klucze i zapisać w bezpiecznym miejscu, ponieważ będą potrzebne w kolejnych krokach.
¶ Montowanie bucketu w Nextcloud:
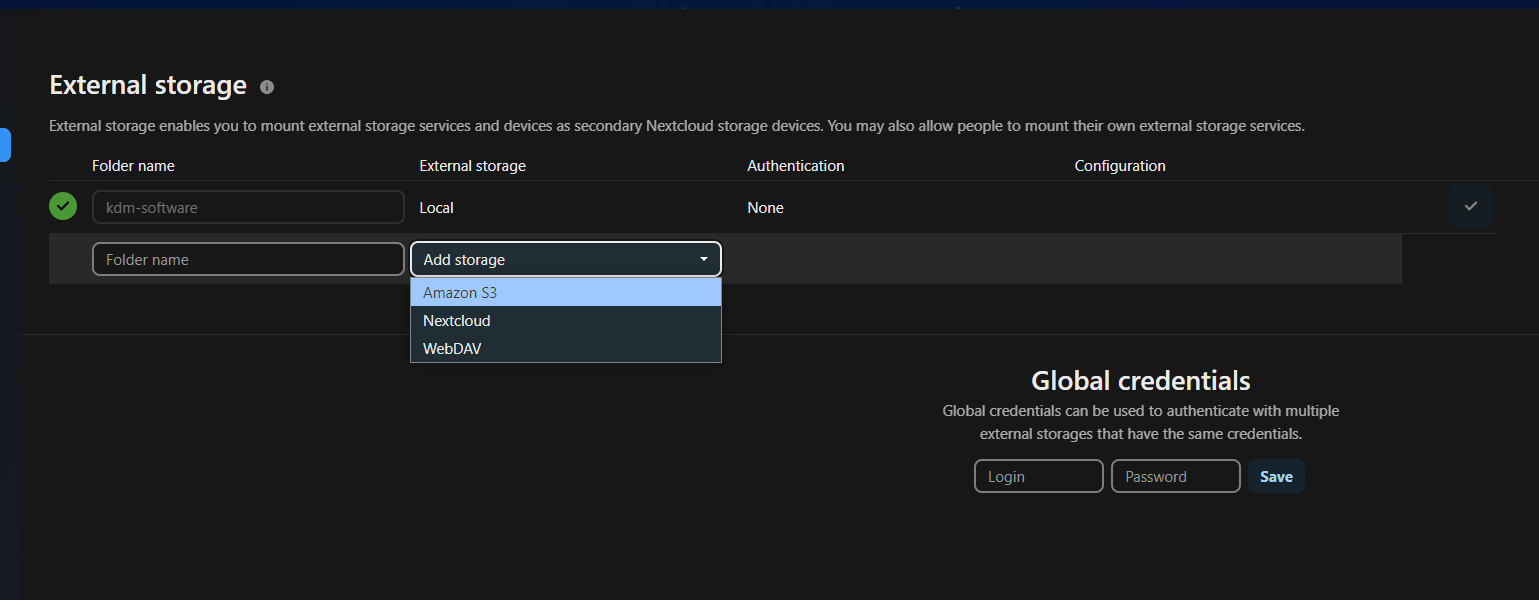
- Należy wejść https://nextcloud.e-science.pl/index.php/settings/user/externalstorages a następnie zalogować się do konta e-science
Uzyskamy bezpośrednio do Ustawień dostępu i dodawania bucketów do Magazynu zewnętrznego
- W sekcji konfiguracji magazynu zewnętrznego, należy wpisać nazwę katalogu, pod jaką bucket będzie widoczny w Nextcloud. Z rozwijanego menu, należy wybrać Amazon S3.
- W polu Uwierzytelnianie, należy wybrać Klucz dostępu.
- W polu Kosz(bucket), należy wpisać nazwę bucketu, który został wybrany podczas procesu Generowania kluczy dostępu.
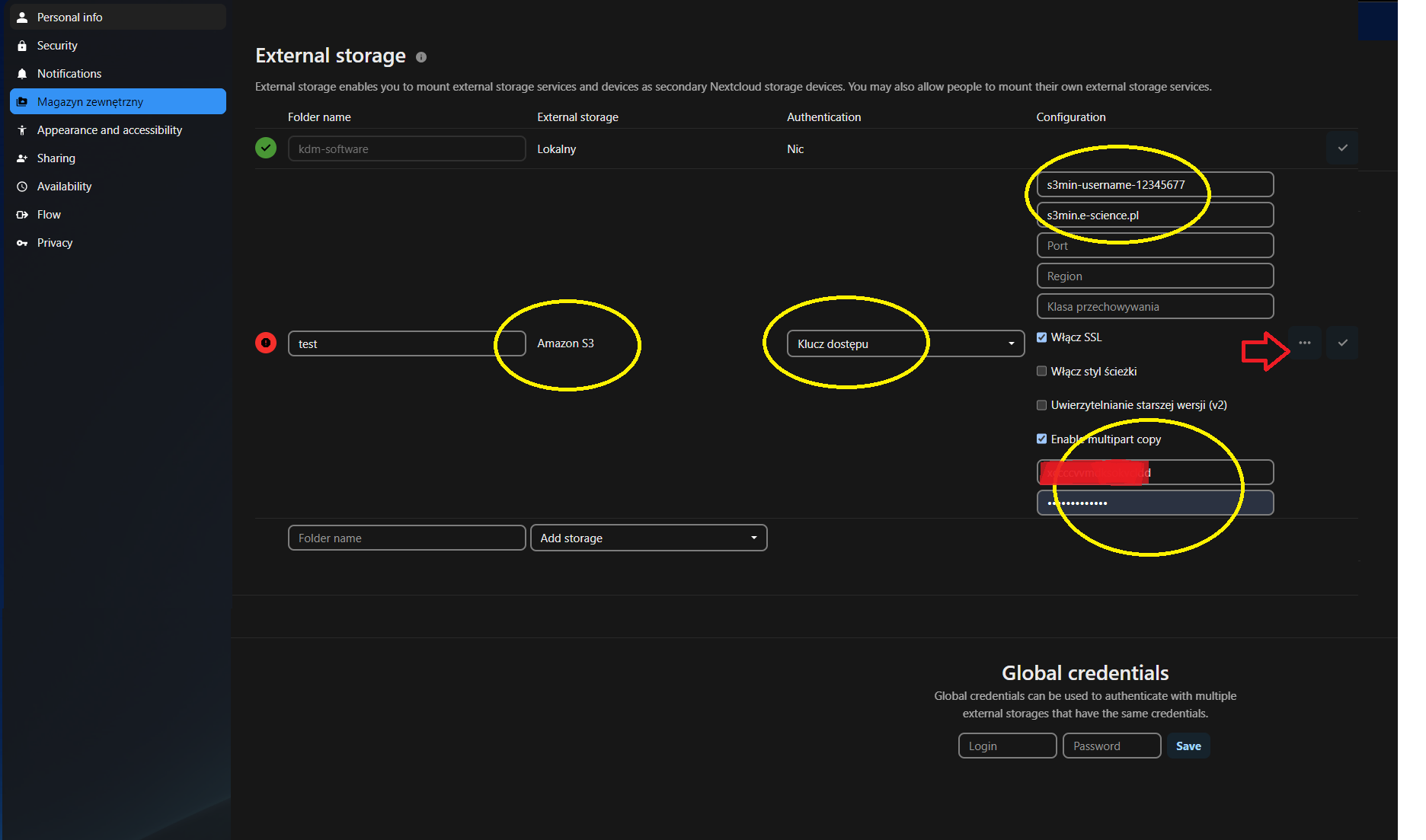
-
W polu Nazwa serwera, należy wpisać adres panelu administracyjnego pozyskanego z Generowania kluczy dostępu. Adres należy wpisać bez informacji o protokole "https://".
-
W polu Klucz dostępu, należy wpisać Access Key, który został wygenerowany zgodnie z instrukcją s3 Generowania kluczy dostępu
-
W polu Klucz tajny, należy wpisać Secret Key
-
Aby umożliwić innym użytkownikom Nextcloud korzystanie z bucketu, należy zaznaczyć opcję Udostępnianie - ENABLE SHARING
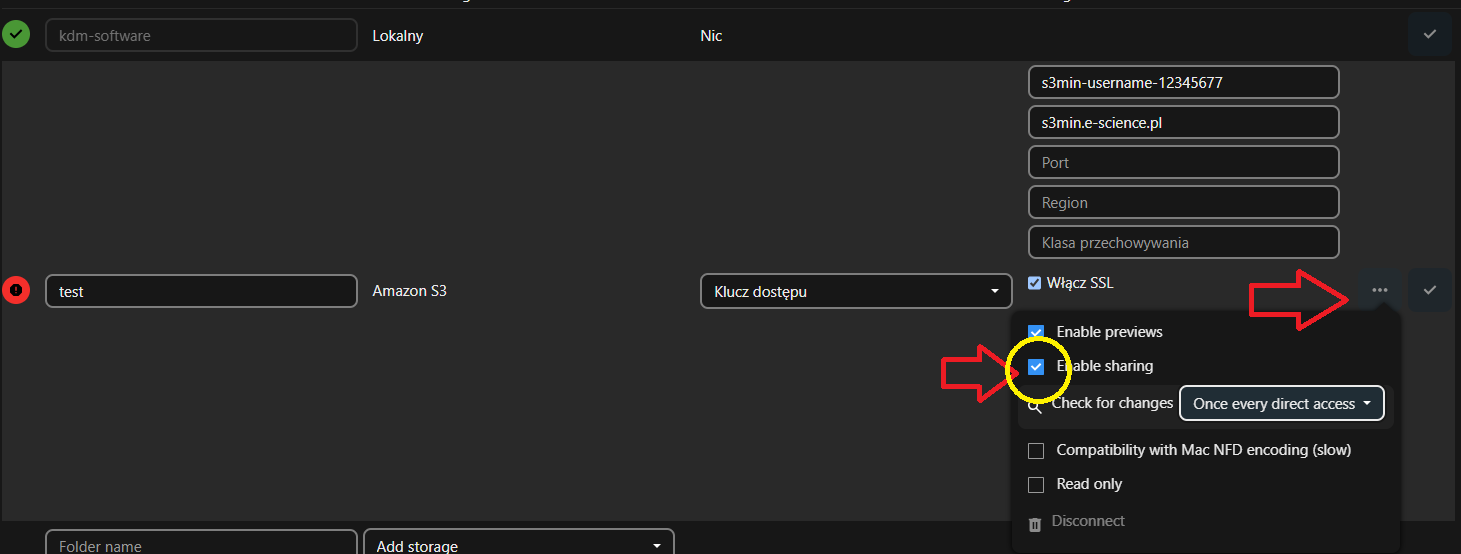
- Po wypełnieniu wszystkich pól, należy kliknąć przycisk Zapisz, aby zakończyć proces konfiguracji.
Jeśli konfiguracja została przeprowadzona poprawnie, powinna pojawić się zielona ikona obok nazwy katalogu, co oznacza, że bucket został poprawnie podłączony.

- Bucket S3 będzie teraz dostępny w Nextcloud jako zwykły katalog, w którym można przechowywać i zarządzać plikami jak w każdym innym folderze w Nextcloud.
¶ s3fs
Podstawowe użytkowanie programu s3fs sprowadza się do montowania dysku za pomocą komendy:
$ s3fs <BUCKETNAME> <mountpoint> -o url=<S3_HOST> -o use_path_request_style
gdzie <BUCKETNAME> to nazwa bucketu, <mountpoint> to ścieżka, pod którą chce się zamontować bucket (katalog <mountpoint> powinien istnieć i być pusty), a <S3_HOST> to adres IP serwera S3 (lub nazwa hosta).
Przykładowo:
$ s3fs test_bucket /home/testuser/local_s3_bucket -o url=https://s3min.e-science.pl -o use_path_request_style
Ponadto, program s3fs umożliwia obsługę rozszerzonych atrybutów (ang. xattr), w tym celu podczas montowania należy dodać opcję -o use_xattr, czy szyfrowanie za pomocą protokołu SSE(-C). Więcej informacji o możliwościach programu znajduje się oficjalnej dokumentacji s3fs.
¶ goofys
Podstawowe użytkowanie programu goofys sprowadza się do montowania dysku za pomocą komendy:
$ goofys --endpoint <S3_HOST> <BUCKETNAME> <mountpoint>
gdzie
<BUCKETNAME>to nazwa bucketu,<mountpoint>to ścieżka, pod którą chce się zamontować bucket (katalog<mountpoint>powinien istnieć i być pusty)<S3_HOST>to adres IP serwera S3 (lub nazwa hosta).
Przykładowo:
$ goofys --endpoint https://s3min.e-science.pl test_bucket /home/testuser/local_s3_bucket
¶ Odmontowywanie
UWAGA! Po zakończeniu korzystania z zamontowanego bucketu należy go odmontować!
W przypadku administratorów systemu, można skorzystać z komendy umount, a w przypadku nieuprzywilejowanych użytkowników, komendy fusermount:
#### dla administratorów ####
# umount /home/testuser/local_s3_bucket
#### dla użytkowników ####
$ fusermount -u /home/testuser/local_s3_bucket
¶ Montowanie bucketu S3 na superkomputerze
Na Superkomputerze możliwe jest zamontowanie bucketu S3 z wykorzystaniem programów s3fs oraz goofys, np. w celu transferu plików generowanych (bądź odczytywanych) przez daną aplikację obliczeniową. Montowanie bucketu S3 jest możliwe jedynie na węzłach obliczeniowych (po przydzieleniu zasobów przez system kolejkowy SLURM, np. poprzez zadanie interaktywne), tzn. nie można zamontować bucketu S3 na węźle dostępowym ui.wcss.pl.
W celu lokalnego zamontowania bucketu S3 na węźle obliczeniowym, należy wykonać następujące czynności:
-
Uzyskać dostęp do węzła obliczeniowego od systemu kolejkowego SLURM, np. poprzez interaktywne zadanie z wykorzystaniem komendy
srun -I, lub poprzez wysłanie zadania obliczeniowego w formie skryptu sbatch. -
Utworzyć katalog
.awsw swoim katalogu domowym (jeśli nie istnieje):
$ mkdir ~/.aws/
- Utworzyć plik z danymi do uwierzytelniania pod ścieżką
~/.aws/credentials(jeśli nie istnieje):
$ vim `~/.aws/credentials`
[default]
aws_access_key_id = ACCESS_KEY_ID
aws_secret_access_key = SECRET_ACCESS_KEY
- Utworzyć katalog, w którym zamontowany zostanie bucket S3 (jeśli nie istnieje), przykładowo:
$ mkdir /home/username/local_s3_bucket
- Wczytać odpowiedni moduł programu
s3fsalbogoofys:
- komenda dla
s3fs:
$ module load s3fs
- komenda dla
goofys:
$ module load goofys
- Zamontować bucket S3 za pomocą
s3fsalbogoofys:
- komenda dla
s3fs:
$ s3fs test_bucket /home/testuser/local_s3_bucket -o url=https://s3min.e-science.pl -o use_path_request_style
- komenda dla
goofys:
$ goofys --endpoint https://s3min.e-science.pl test_bucket /home/testuser/local_s3_bucket
- Po zakończeniu pracy z bucketem S3, ale przed zakończeniem zadania obliczeniowego, należy odmontować dysk:
$ fusermount -u /home/testuser/local_s3_bucket
¶ Podziękowania dla WCSS
Zgodnie z regulaminem usługi, wszelkie publikacje, w tym prace doktorskie i dyplomowe, które powstały m.in. dzięki użyciu usługi „Przechowaj dane w chmurze”, powinny zawierać podziękowania postaci (odpowiednio do języka publikacji):
"Opracowano przy użyciu zasobów udostępnionych przez Wrocławskie Centrum Sieciowo-Superkomputerowe (http://wcss.pl)”
"Created using resources provided by Wroclaw Centre for Networking and Supercomputing (http://wcss.pl)"